作者:阿夫辛·尼克塔什、維克多·洛格諾夫
摘要 :
音訊助手在從家用到汽車和工業產品和物聯網的各種應用中變得非常流行。此類設備不斷監聽周圍環境,並在預先訓練的關鍵字上喚醒以執行某些命令。功耗是許多此類資源受限的邊緣應用的關鍵因素,在這些應用中,連接到雲以處理原始數據是不可行的。MAX78000是新一代人工智慧(AI)微控制器,使神經網路能夠以超低功耗執行,並生活在物聯網邊緣。本文展示了在MAX78000上實現關鍵字識別應用。機器學習模型在PyTorch上採用Maxim的開發流程構建,使用具有20個關鍵字的Google語音命令數據集子集進行訓練,並部署在MAX78000EVKIT上。
介紹
近年來,由語音啟動使用者介面驅動的數位助理的應用急劇增加。雖然某些產品嚴重依賴雲端連接在功能強大的遠端伺服器上執行語音辨識演算法和自然語言處理,但在低功耗設備中,將音訊不斷流式傳輸到雲端進行處理是不可行的。特別是,喚醒關鍵字的檢測以及一組有限的命令詞預計將在本地完成,以優化功耗並減少物聯網和邊緣應用中的延遲。MAX78000是一款具有卷積神經網路(CNN)加速器的超低功耗微控制器,可有效滿足此類應用需求。
CNN在建模聲學系統方面非常受歡迎,尤其是關鍵字檢測。CNN與常規神經網路一樣,被構造為一系列具有權重和偏差的神經元,然後是非線性。然而,卷積層一次只能查看具有最後一層輸出神經元一小部分的局部區域,並在每次執行時將其滑動到最後一層(圖 1)。池化層經常與CNN結合使用,以對最後一層輸出進行下採樣。這些操作是MAX78000 CNN架構的核心,該架構採用64個並行處理器,每個處理器都有一個彙集單元、一個捲積引擎和一個專用的重量記憶體。
本應用筆記探討如何在帶有CNN加速器的超低功耗微控制器MAX78000上實現關鍵字識別應用。從第二版Google語音命令數據集中選擇了20個關鍵字,以訓練關鍵字識別演示(KWS20)。
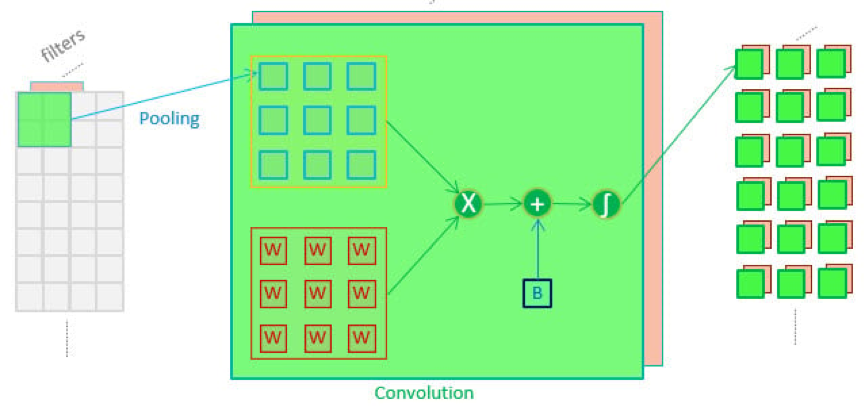 圖1.美國有線電視新聞網的基本操作。
圖1.美國有線電視新聞網的基本操作。
MAX78000
MAX78000 [1]是新一代人工智慧(AI)微控制器,使神經網路能夠以超低功耗執行,並生活在物聯網邊緣。該產品將最節能的AI處理與Maxim經過驗證的超低功耗微控制器相結合。基於硬體的 CNN 加速器使電池供電的應用程式能夠執行 AI 推理,同時僅消耗微焦耳的能量。這使其成為關鍵字發現應用程式的理想架構。MAX78000具有帶FPU CPU的Arm® Cortex-M4®,通過超低功耗深度神經網路加速器實現高效的系統控制。 圖2所示為MAX78000的頂層架構。
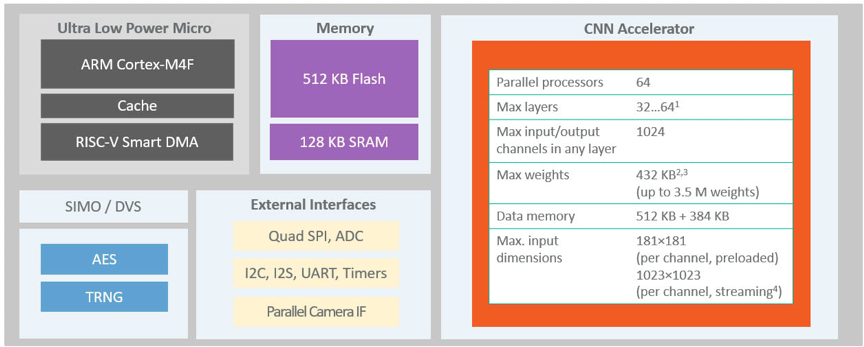 圖2.MAX78000的結構
圖2.MAX78000的結構
MAX78000評估板提供了一個平臺,利用MAX78000的功能構建新一代AI器件。評估板具有板載硬體,如數字麥克風、串行埠、攝像頭模組支援和3.5英寸觸摸彩色薄膜晶體管(TFT)顯示幕[2](圖3),用於KWS20演示應用。
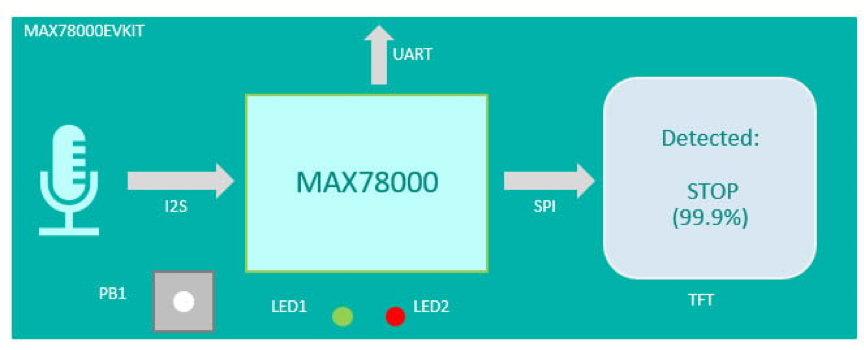 圖3.MAX78000評估板上的關鍵詞識別演示
圖3.MAX78000評估板上的關鍵詞識別演示
MAX78000開發流程
PyTorch或TensorFlow-Keras工具鏈可用於開發MAX78000的模型。該模型是使用一系列表示硬體的已定義子類創建的。池化或啟動等一些操作融合到 1D 或 2D 捲積層以及全連接層。還添加了捨入和剪裁以匹配硬體。
該模型使用浮點權重和訓練數據進行訓練。權重可以在訓練期間(量化感知訓練)或訓練后(訓練後量化)量化。可以在評估數據集上評估量化結果,以檢查由於權重量化而導致的精度下降。
MAX78000合成器工具(ai8xize)接受PyTorch檢查點或TensorFlow導出的ONNX檔作為輸入,以及YAML格式的模型描述。還向合成器提供了一個示例數據檔(.npy檔),以驗證硬體上的合成模型。將此數據的推理結果與預合成模型的預期輸出進行比較。
MAX78000頻率合成器自動生成C代碼,可在MAX78000上編譯和執行。C 代碼包括應用程式程式設計介面 (API) 調用,用於將權重以及提供的範例數據載入到硬體,以對範例數據執行推理,並將分類結果與預期結果進行比較,作為通過/失敗健全性測試。此生成的 C 代碼可用作創建自己的應用程式的範例。圖4顯示了MAX78000的整體開發流程。
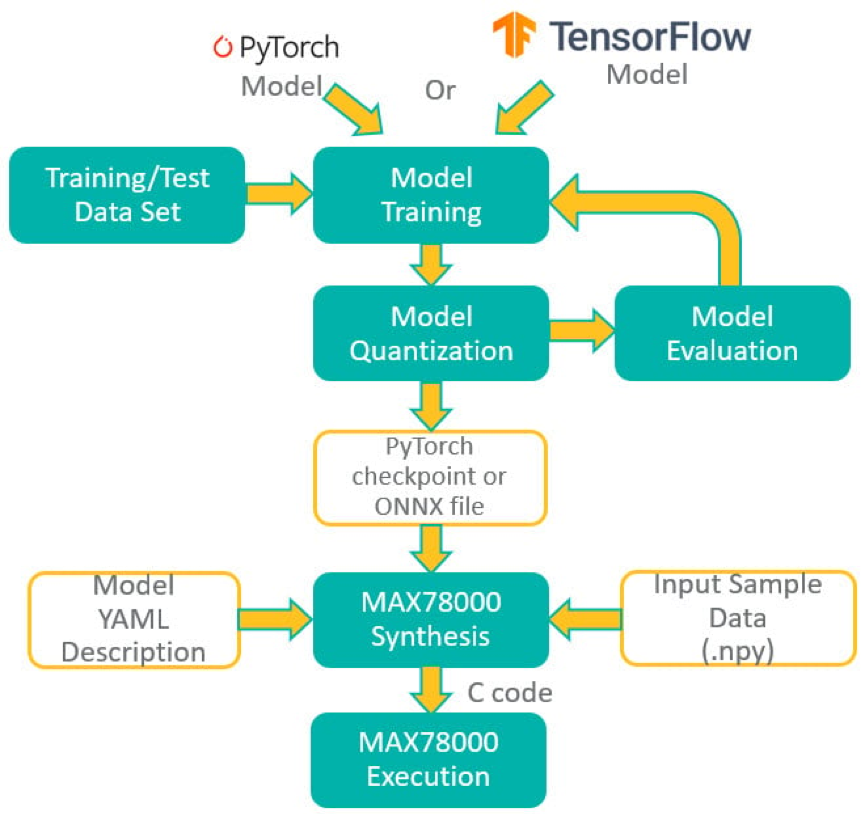 圖4.MAX78000的開發流程
圖4.MAX78000的開發流程
關鍵詞發現方法:
1. 梅爾頻率倒譜係數特徵提取
梅爾頻率倒譜係數(MFCC)是眾所周知和流行的特徵提取方法之一[3]。特徵提取的目的是用一組已知和相關元件來表示語音信號以進行分類。
MFCC是通過使用濾波器組的信號分解來實現的。它提供了 Mel 頻率標度上短期能量實對數的離散餘弦變換 (DCT)。更具體地說,MFCC 的計算流水線包括將語音信號視窗化為幀,執行快速傅立葉變換 (FFT) 以查找每個幀的功率譜,使用 Mel 標度進行濾波器組處理,最後在功率譜的對數刻度上進行 DCT(圖 5)。
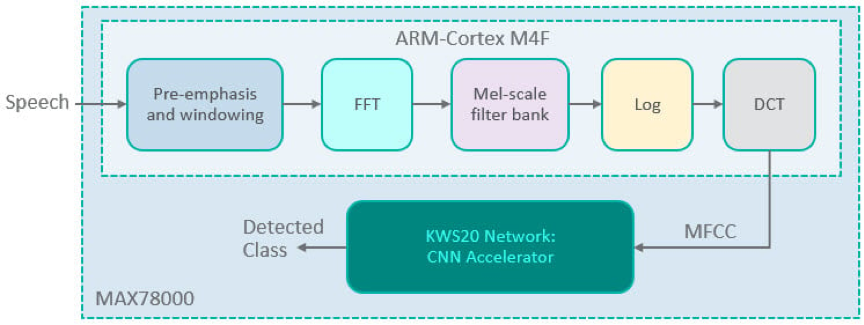 圖5.Arm 上的 MFCC 處理(初始模型)。
圖5.Arm 上的 MFCC 處理(初始模型)。
語音數據在微控制器上預處理,以生成MFCC以採用這種方法。FFT、濾波、日誌和DCT必須在MAX78000的ARM處理器固件中實現。接下來,CNN 對語音數據樣本的 MFCC 執行推理。最初針對此應用程式研究了此模型。
2. 使用 CNN 的 MFCC 近似
研究了另一種方法來創建兩個獨立的CNN並提高效率。訓練了MFCC估計器網路(Melspectogram網路)以提供給定波形的實際MFCC的近似值。使用第二個KWS20分類器網路對估計的MFCC中的關鍵字進行分類。CNN加速器在這種方法中依次運行MFCC和KWS20網路。MFCC 操作將時序樣本轉換為二維 (2D) 空間。這是使用一系列一維捲積層建模的。KWS20 分類器接收類似 2D 圖像的數據,並將其傳遞到幾個 2D 卷積層。
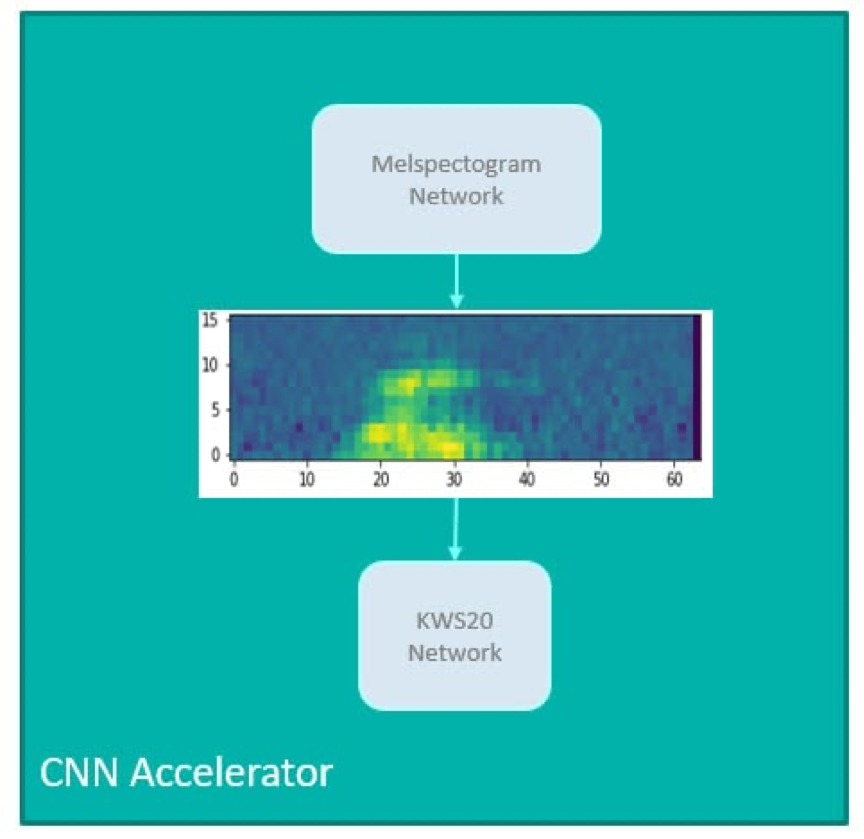 圖6.CNN上的MFCC近似(第二種方法)。
圖6.CNN上的MFCC近似(第二種方法)。
3. 使用 CNN 進行原始數據處理
在第三種演示方法中使用原始數據訓練單個組合網路以識別類,而不是為MFCC和分類提供兩個單獨的CNN。此方法簡化了訓練並減小了網路的大小,而不會顯著降低性能。該網路包括一系列模仿MFCC近似器的1D卷積層,然後是一些2D卷積層。末尾的密集層生成每個類的最大可能性。選擇這種方法(圖 7)來構建 KWS20 演示,如以下各節所述。
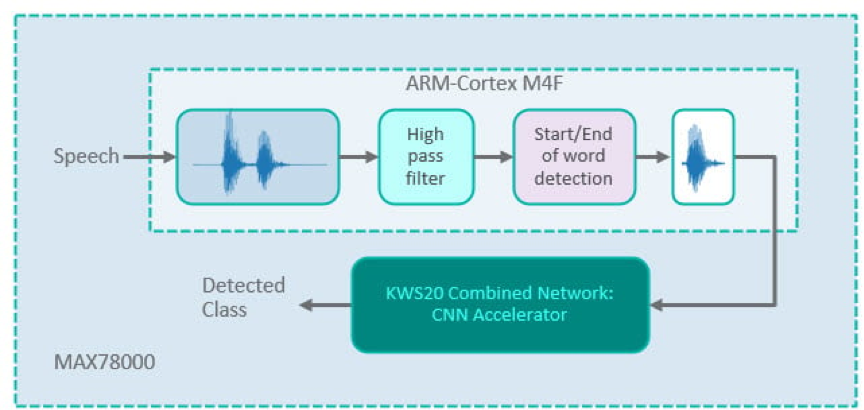 圖7.演示模型:將CNN與原始數據相結合作為輸入。
圖7.演示模型:將CNN與原始數據相結合作為輸入。
數據集和增強
本練習使用谷歌創建的語音命令數據集的第 2 版 [4][5]。該數據集由超過 100k 個 35 個不同單詞的話語組成,存儲為以 16kHz 采樣的一秒 .wave 格式檔。35 個單詞中有 20 個被選為所需類,其餘標記為未知類。 表 1 顯示了所選關鍵字。
表 1:演示中選定的 20 個關鍵字集
|
類代碼 |
詞 |
話語數 |
類代碼 |
詞 |
話語數 |
類代碼 |
詞 |
話語數 |
|
0 |
向上 |
3723 |
7 |
不 |
3941 |
14 |
五 |
4052 |
|
1 |
下 |
3917 |
8 |
上 |
3845 |
15 |
六 |
3860 |
|
2 |
左 |
3801 |
9 |
關閉 |
3745 |
16 |
七 |
3998 |
|
3 |
右 |
3778 |
10 |
一 |
3890 |
17 |
八 |
3787 |
|
4 |
停 |
3872 |
11 |
二 |
3880 |
18 |
九 |
3934 |
|
5 |
去 |
3880 |
12 |
三 |
3727 |
19 |
零 |
4052 |
|
6 |
是的 |
4044 |
13 |
四 |
3728 |
20 |
未知 |
28375 |
未知類的話語數明顯高於其他類,因為它包括所有剩餘 15 個類的聚合。與其他類相比,這導致未知類的過度訓練。交叉熵損失函數(PyTorch)中未知類的權重設置為其他類權重的0.14,以解決此問題。
每個波形通過額外的雜訊、時移和隨機拉伸進行兩次增強,以進一步增強數據集,從而使數據集大小是原始數據集大小的 3 倍。增強功能提高了具有背景雜訊的真實環境中的網路性能。圖 8 說明瞭增強前後的 Stop 語句示例。
增強數據集被劃分為訓練、驗證和測試類別(表 2)。
預設的 TensorFlow 數據格式是通道最後。Conv1D 操作的預期輸入形狀為batch_size、寬度和通道,Conv2D 操作為batch_size、高度、寬度和通道。
樣本按順序讀取並存儲在 128 行中,以製作 1 x 128 x 128 張量用於訓練目的。圖 9-a 顯示了 Stop 數據樣本在發送到 CNN 之前的圖像表示。
另一方面,合成器的格式是通道優先,就像 PyTorch 一樣。訓練文本為每個類生成一個範例示例數據檔,供合成器用於驗證。這些範例類數據檔通過轉置數據集示例轉換為通道優先格式。圖9-b顯示了合成器轉置的相同樣品。
表 2:KWS20 數據集大小
|
類別 |
話語數 |
|
訓練 |
197751 |
|
驗證 |
21972 |
|
測試 |
68250 |
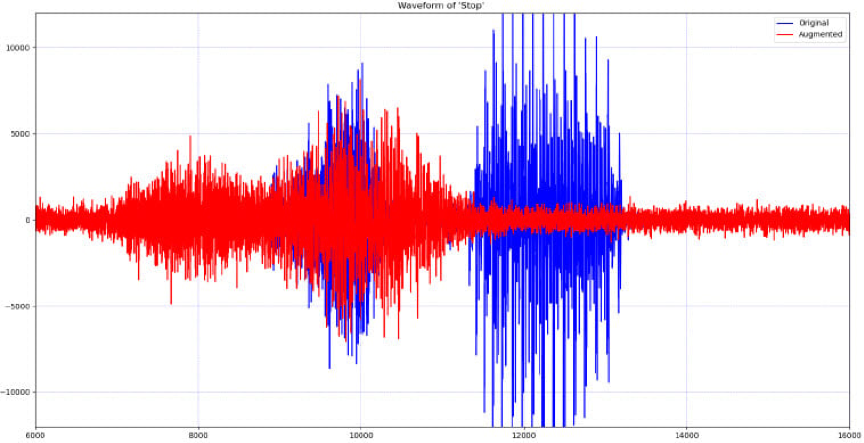 圖8.增強前後的停止波形。
圖8.增強前後的停止波形。
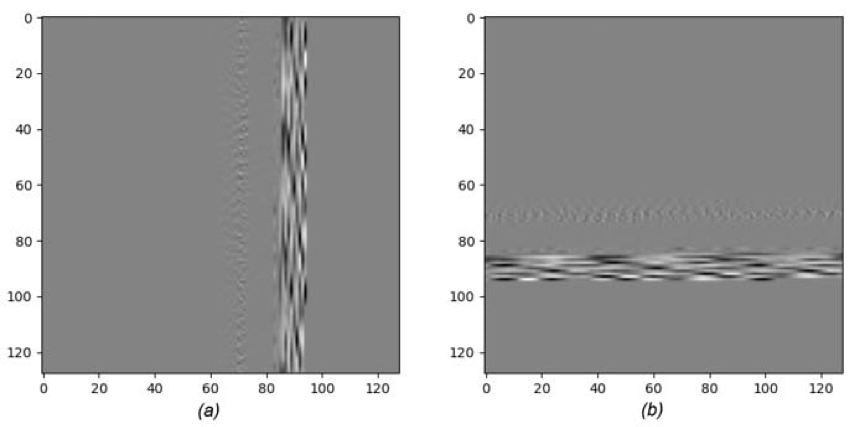 圖9.由 128 x 128 影像表示的停止波形:
圖9.由 128 x 128 影像表示的停止波形:
-
被饋送到網路進行培訓。
-
轉置以與合成腳本一起使用。
CNN 模型訓練
訓練組合關鍵字發現CNN對原始數據進行分類。該模型由兩個背靠背的CNN組成:1D(Conv1D)和2D(Conv2D)卷積網路。Conv1D CNN包括四層並提取語音特徵。Conv2D CNN 包括五層,然後是用於對話語進行分類的全連接層。該模型使用20個關鍵字的增強數據集進行訓練(表1)。圖 10 顯示了 CNN 模型。
 圖 10.PyTorch 中的關鍵字發現模型
圖 10.PyTorch 中的關鍵字發現模型
模型訓練由以下文稿執行:
(ai8x-training) $ ./train_kws20.sh
該腳本會自動下載Google語音命令版本2數據集,使用上述增強技術對其進行擴展,然後完成訓練。圖 11 顯示了模型訓練的結果。
 圖 11.模型訓練範例
圖 11.模型訓練範例
CNN 模型量化
訓練期間生成的CNN權重必須量化為8位。CNN 權重量化是通過執行以下腳本完成的:
(ai8x-synthesis) $ ./quantize_kws20.sh
可以通過執行以下腳本來評估量化模型:
(ai8x-training) $ ./evaluate_kws20.sh
圖 12 顯示了模型評估的結果。
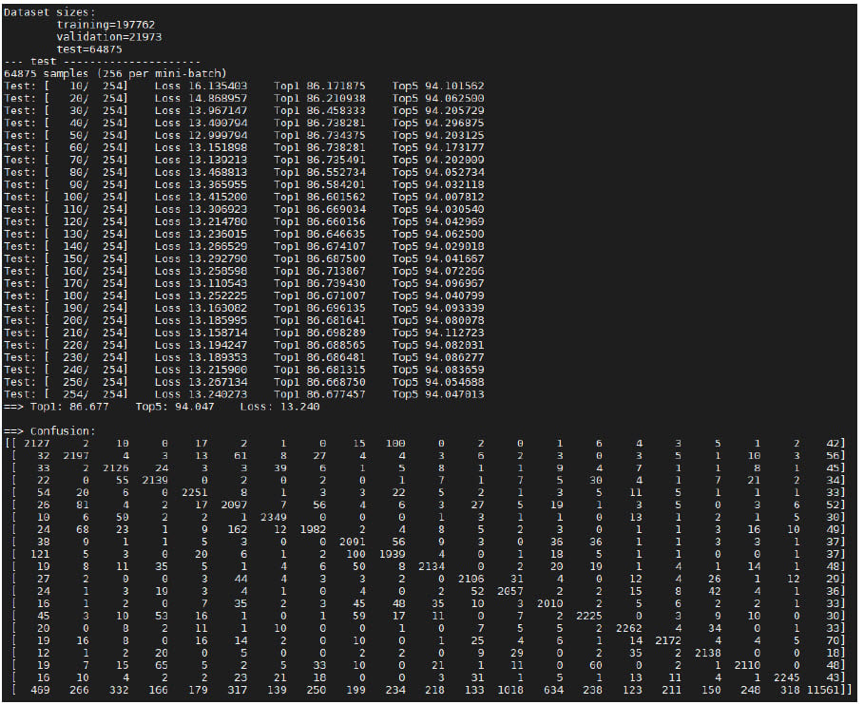 圖 12.量化後的模型評估和混淆矩陣示例。
圖 12.量化後的模型評估和混淆矩陣示例。
CNN 模型合成
網路綜合腳本生成通過/失敗示例C代碼,其中包括初始化MAX78000 CNN加速器、載入量化CNN權重以及提供的輸入樣本以及卸載分類結果以與預期輸出進行比較的必要功能。合成工具需要三個輸入(圖 4):
-
量化的 PyTorch 檢查點檔或 TensorFlow 模型導出為 ONNX 格式。
-
網路模型 YAML 說明。
-
一個示例輸入,其中包含要包含在生成的 C 代碼中進行驗證的預期結果。
合成腳本生成如圖 13 所示的輸出檔。
 圖 13.生成MAX78000示例原始程式碼。
圖 13.生成MAX78000示例原始程式碼。
示例代碼可以編譯並部署到MAX78000中。圖 14 顯示了執行結果以及每個類的置信度。
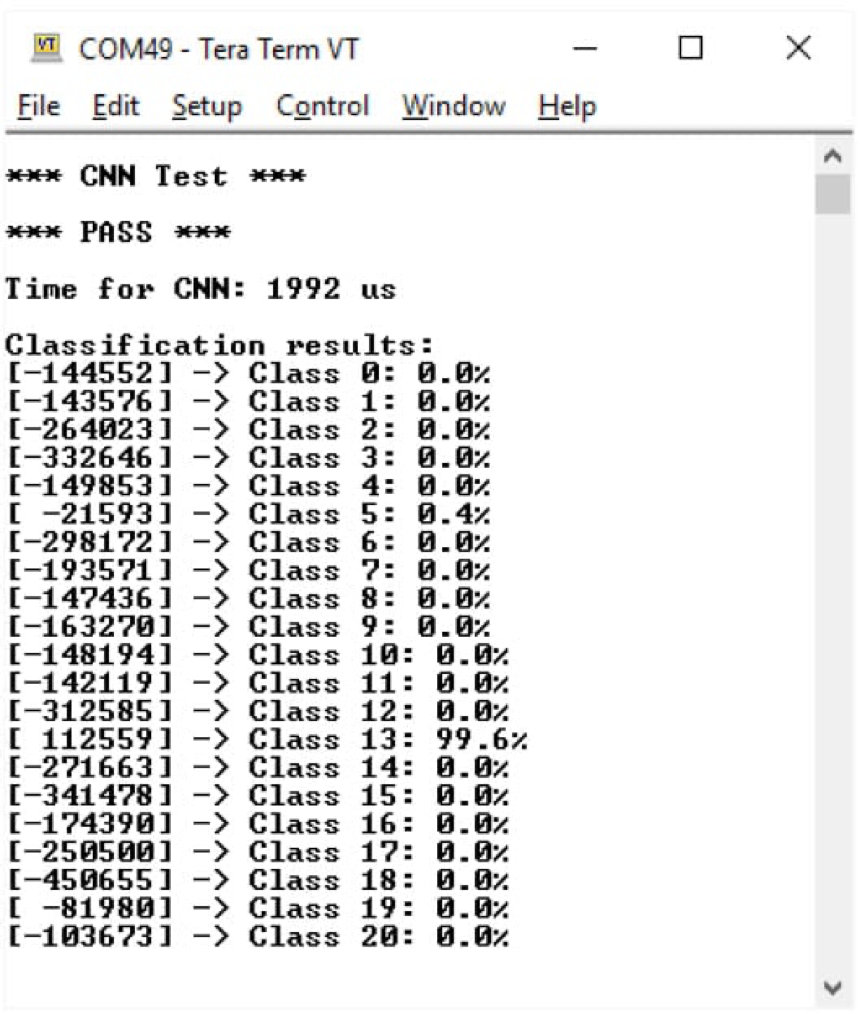 圖 14.關鍵字發現模型執行結果。
圖 14.關鍵字發現模型執行結果。
準系統C代碼作為構建KWS20演示平台的基礎。用於載入/卸載權重和樣本的CNN初始化、權重(內核)和説明程式函數從生成的範例代碼移植到下一節所述的 KWS20 演示中。
KWS20 演示平臺
KWS20固件演示了MAX78000評估板上關鍵字的檢測,如圖15所示。板載I2S麥克風采樣18位、16kHz音訊信號,並流式傳輸到MAX78000。一個簡單的高通濾波器用於消除麥克風的直流偏移,並將樣本存儲在圓形緩衝器中。信號電平在 128 個樣本視窗上取平均值,並與可調閾值進行比較以查找單詞的開頭。低於此閾值的級別被歸類為話語中單詞之前的沉默。一旦信號電平超過閾值,就會檢測到單詞的開頭。在CNN加速器上啟動推理需要16kHz、8位採樣(1秒)。監控口語末尾的信號電平。如果幾個背靠背 128 個樣本視窗的平均值水準下降並保持在可調閾值以下,或者如果已經收集了 16k 個樣本,則可以開始推理。CNN加速器對該網路的推理大約需要2.5ms。推理結果和置信度顯示在顯示幕和串行埠 [6] 上。圖 16 總結了 KWS20 演示固件中的處理流程。
 圖 15.MAX78000評估板上的KWS20
圖 15.MAX78000評估板上的KWS20
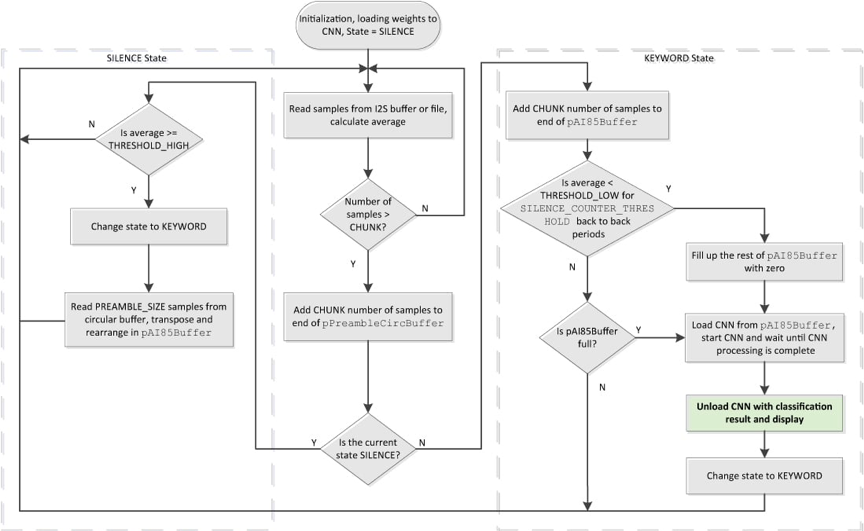 圖 16.KWS20演示韌體的處理流程。
圖 16.KWS20演示韌體的處理流程。
本應用筆記演示了20關鍵字檢測模型的實現,以及針對資源受限的邊緣或物聯網應用的超低功耗MAX78000平台上的最終部署。它還重點介紹了MAX78000架構,並描述了構建機器學習模型的開發流程,將關鍵字發現作為目標應用。
MAX78000
具有超低功耗卷積神經網路加速器的人工智慧微控制器
新一代人工智慧微處理器,旨在使神經網路能夠以超低功耗執行
描述
人工智慧(AI)需要極高的計算能力,但Maxim正在切斷AI洞察的電源線。MAX78000是新一代AI微控制器,使神經網路能夠以超低功耗執行,並生活在物聯網邊緣。該產品將最節能的AI處理與Maxim經過驗證的超低功耗微控制器相結合。我們基於硬體的捲積神經網路 (CNN) 加速器使電池供電的應用程式能夠執行 AI 推理,同時僅消耗微焦耳的能量。
MAX78000是一款先進的片上系統,具有帶FPU CPU的Arm ® Cortex ® -M4,通過超低功耗深度神經網路加速器實現高效的系統控制。CNN 引擎具有 442KB 的權重存儲記憶體,可以支援 1 位、2 位、4 位和 8 位權重(支援高達 350 萬個權重的網路)。CNN權重記憶體是基於SRAM的,因此可以即時進行AI網路更新。CNN引擎還具有512KB的數據記憶體。CNN架構非常靈活,允許網路在PyTorch ® 和TensorFlow ® 等傳統工具集中進行訓練,然後使用Maxim提供的工具在MAX78000上轉換執行。
除了CNN引擎中的記憶體外,MAX78000還為微控制器內核提供大片內系統記憶體,具有512KB快閃記憶體和高達128KB SRAM。支援多個高速和低功耗通信介面,包括I 2 S和並行攝像頭介面(PCIF)。
該元件採用 81 引腳 CTBGA(8mm x 8mm,0.8mm 間距)封裝。
主要特徵
-
雙核超低功耗微控制器
-
Arm Cortex-M4 處理器,FPU 高達 100MHz
-
512KB 快閃記憶體和 128KB SRAM
-
通過 16KB 指令高速緩存優化性能
-
用於 SRAM 的可選糾錯碼 (ECC-SEC-DED)
-
高達 60MHz 的 32 位 RISC-V 協處理器
-
多達 52 個通用 I/O 引腳
-
12 位並行攝像頭介面
-
一個 I 2 S 主/從,用於數位音訊介面
-
-
神經網路加速器
-
針對深度卷積神經網路進行了高度優化
-
442k 8 位重量容量,帶 1,2,4,8 位權重
-
可程式設計輸入圖像尺寸高達1024 x1024像素
-
可程式設計網路深度高達64層
-
可程式設計每層網路通道寬度,多達1024個通道
-
1 維和二維捲積處理
-
流媒體模式
-
靈活支援其他網路類型,包括MLP和遞歸神經網路
-
-
電源管理可最大限度地延長電池應用的工作時間
-
整合單電感多輸出 (SIMO) 開關模式電源 (SMPS)
-
2.0V至3.6V SIMO電源電壓範圍
-
動態電壓調節可最大限度地降低有源內核功耗
-
22.2μA/MHz,在 3.0V 時從高速緩存執行環路(僅限 CM4)
-
在啟用即時時鐘 (RTC) 的低功耗模式下可選擇 SRAM 保持
-
-
安全性和完整性
-
可用的安全啟動
-
AES 128/192/256 硬體加速引擎
-
真隨機數生成器 (TRNG) 種子產生器
-
應用/用途
-
物件檢測和分類
-
音訊處理:多關鍵字識別、聲音分類、降噪
-
面部識別
-
時間序列數據處理:心率/健康信號分析、多感測器分析、預測性維護
聯繫我們
ADI 所有產品請洽【 安馳科技 】
安馳科技|ADI亞德諾半導體網站:https://anstekadi.com
安馳科技 LINE 官方帳號:https://lin.ee/5gcKNi7
安馳科技 Facebook 官方帳號:https://www.facebook.com/ANStek3528
安馳科技EDM訂閱 https://anstekadi.com/Home/EDM
申請樣品與技術支援:https://www.surveycake.com/s/dQ3Y2
與我聯絡:Marketing.anstek@macnica.com




